
Sora横空出世,仅仅是生成视频那么简单?业内人士:通用人工智能或在一年左右实现(组图)
“两只金毛猎犬在山顶播客”
“火星上日落时的一场极具未来感的无人机比赛”
“在一个与自然和谐共生,同时又有超强朋克气质和高科技属性的未来城市漫游……”
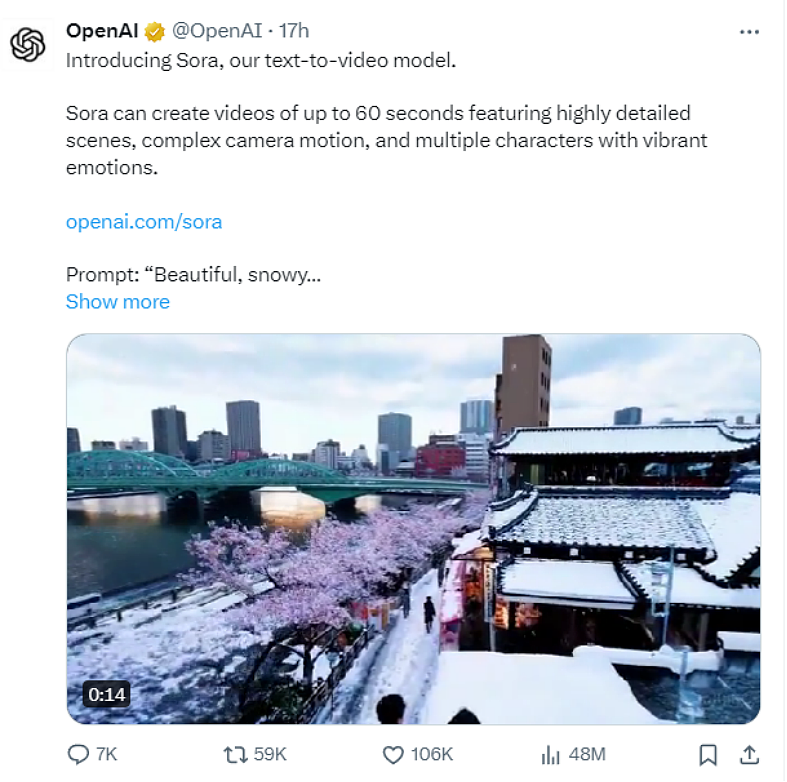
根据上述提示词,OpenAI首席执行官阿尔特曼在X平台上发布了一系列视频,精美的场景让用户惊叹不已。而这些视频全都是通过OpenAI 2月15日发布的最新视频生成模型Sora制作的,用户震惊之余,也给予了Sora高度评价,将其描述为“绝无仅有”和“游戏规则改变者”。
 图片来源:X平台
图片来源:X平台
Sora采用了OpenAI文生图模型DALL-E 3背后的强大技术,可将简短的文本描述转化成长达1分钟的高清视频。业界大佬Gabor Cselle将Sora和Pika、RunwayML和Stable Video进行对比后发现,在输入相同的提示后,其他主流工具生成的视频都大约只有5秒钟,Sora可以在一段长达17秒视频场景中,保持动作和画面一致性。
英伟达人工智能研究院首席研究科学家Jim Fan也对Sora的能力发出感叹,称这是视频生成领域的GPT-3时刻。他表示,Sora是一个“数据驱动的物理引擎”,一个可学习的模拟器或“世界模型”。360集团创始人、董事长周鸿祎则称,随着Sora的到来,人类离AGI(通用人工智能)真的就不远了,不是10年、20年的问题,可能一两年很快就可以实现。
在随后发布的技术报告中,OpenAI介绍了Sora的强大性能以及背后的支撑技术,也对Sora的局限性进行了客观的分析。《每日经济新闻》记者通过梳理,总结出了Sora的六大核心优势。
从技术上看,Sora有望将数字内容的创造力和真实感提升到新的水平,但凡事总有两面性,影视、广告制作和视频等行业也将面临严重的冲击。另外,有专家对于技术的迅猛发展也表示出了担忧,称这类技术可能会导致“深度伪造”视频,让人难以识别,产生滥用等问题。
技术报告揭秘Sora六大核心优势
值得注意的是,Sora推出的同一天,谷歌发布了Gemini多模态模型的更新版本,而三天前,Stability AI推出了新的图像生成模型Stable Cascade。OpenAI的最新举动无疑将加剧生成式AI图片和视频领域的竞争。
而在Sora推出后不久,OpenAI发布了这款新工具的技术报告。在报告中,OpenAI首先重点介绍了如何将不同类型的视觉数据转化为统一的格式,以便于对生成模型进行大规模训练的方法,并对Sora的能力和局限性进行了评价。
 图片来源:Sora技术报告
图片来源:Sora技术报告
《每日经济新闻》记者经过对报告的梳理,总结出了Sora的6大优势:
(1)准确性和多样性:Sora可将简短的文本描述转化成长达1分钟的高清视频。它可以准确地解释用户提供的文本输入,并生成具有各种场景和人物的高质量视频剪辑。它涵盖了广泛的主题,从人物和动物到郁郁葱葱的风景、城市场景、花园,甚至是水下的纽约市,可根据用户的要求提供多样化的内容。另据Medium,Sora能够准确解释长达135个单词的长提示。
(2)强大的语言理解:OpenAI利用Dall-E模型的re-captioning(重述要点)技术,生成视觉训练数据的描述性字幕,不仅能提高文本的准确性,还能提升视频的整体质量。此外,与DALL·E 3类似,OpenAI还利用GPT技术将简短的用户提示转换为更长的详细转译,并将其发送到视频模型。这使Sora能够精确地按照用户提示生成高质量的视频。
(3)以图/视频生成视频:Sora除了可以将文本转化为视频,还能接受其他类型的输入提示,如已经存在的图像或视频。这使Sora能够执行广泛的图像和视频编辑任务,如创建完美的循环视频、将静态图像转化为动画、向前或向后扩展视频等。OpenAI在报告中展示了基于DALL·E 2和DALL·E 3的图像生成的demo视频。这不仅证明了Sora的强大功能,还展示了它在图像和视频编辑领域的无限潜力。
(4)视频扩展功能:由于可接受多样化的输入提示,用户可以根据图像创建视频或补充现有视频。作为基于Transformer的扩散模型,Sora还能沿时间线向前或向后扩展视频。从OpenAI提供的4个demo视频看,都从同一个视频片段开始,向时间线的过去进行延伸。因此,尽管开头不同,但视频结局都是相同的。
(5)优异的设备适配性:Sora具备出色的采样能力,从宽屏的1920x1080p到竖屏的1080x1920,两者之间的任何视频尺寸都能轻松应对。这意味着Sora能够为各种设备生成与其原始纵横比完美匹配的内容。而在生成高分辨率内容之前,Sora还能以小尺寸迅速创建内容原型。
(6)场景和物体的一致性和连续性:Sora可以生成带有动态视角变化的视频,人物和场景元素在三维空间中的移动会显得更加自然。Sora 能够很好地处理遮挡问题。现有模型的一个问题是,当物体离开视野时,它们可能无法对其进行追踪。而通过一次性提供多帧预测,Sora可确保画面主体即使暂时离开视野也能保持不变。
 图片来源:Sora技术报告
图片来源:Sora技术报告
据外媒报道,Sora的推出标志着AI研究的一个重要里程碑。凭借其模拟和理解现实世界的能力,Sora为未来实现通用人工智能(AGI)奠定了基础。从本质上讲,Sora不仅仅是生成视频,而是在突破AI所能完成的极限。
伊利诺伊大学厄巴纳-香槟分校信息科学教授Ted Underwood表示:“就算是在未来的2-3年,我也没想过视频制作可以达到这样持续、连贯的水平。”他表示,与其他文本到视频工具相比,“容量似乎有所提升”。
OpenAI CEO阿尔特曼在X平台上透露,Sora目前已向红队成员(red teamers,指的是误导信息、仇恨内容和偏见内容等方面的专家)和部分创意人士开放。
业内人士:Sora可能让AGI在1年左右实现
英伟达人工智能研究院首席研究科学家Jim Fan则在X平台发文表示,“如果你还是把Sora看成DALLE那样的生成式玩具,还是好好想想吧,这是一个数据驱动的物理引擎。他是对许多世界的模拟,无论是真实的还是幻想的。”他认为,Sora是一个可学习的模拟器,或“世界模型”。
在他看来,Sora代表了文本生成视频的GPT-3 时刻。而针对部分称“Sora并没有学习物理,仅仅是在二维空间里对像素进行操作”的声音,他表示,Sora所展现的软物理仿真实际上是一种随着规模扩大而出现的特性。Sora 必须学习一些隐式的文本到 3D、3D 变换、光线追踪渲染和物理规则,才有可能精确地模拟视频像素。它必须理解游戏引擎的概念,才有可能生成视频。
 图片来源:X平台
图片来源:X平台
在前女友格莱姆斯的一条推文下方,马斯克回应称:“有了AI加持的人类将在未来几年里创造出最好的作品。” 格莱姆斯在X平台上发布了多条推文,讨论OpenAI这项新技术对电影以及更广泛的艺术创作的影响。此外,有网友在评论Sora生成的60秒时尚女子在东京街头散步时称,“gg Pixar(皮克斯动画制作公司)”(编注:gg为Good Games缩写,代指“打得好,我认输” ),随后马斯克回复,“gg humans(人类)”。
 图片来源:X平台
图片来源:X平台
对于Sora的最大优势,360集团创始人、董事长周鸿祎说,“这次OpenAI利用它的大语言模型优势,让Sora实现了对现实世界的理解和对世界的模拟两层能力,这样产生的视频才是真实的,才能跳出2D的范围模拟真实的物理世界。”他同时称,“一旦人工智能接上摄像头,把所有的电影都看一遍,把YouTube上和 TikTok 的视频都看一遍,对世界的理解将远远超过文字学习,一幅图胜过千言万语,这就离AGI真的就不远了,不是10年、20年的问题,可能一两年很快就可以实现。”
影视等行业面临颠覆
然而,Sora在带来无限可能的同时,也将对部分行业产生巨大的影响,包括影视、广告制作、教育、游戏、新闻和动画等领域。
谈及Sora的行业冲击时,Jim Fan评价道,Sora的物理学理解目前还是脆弱的,远非完美。它仍然会产生幻觉,生成与物理常识不符的事物,还没有很好地掌握物体交互的原理。
周鸿祎对此也深以为然,他指出,AI不一定那么快颠覆所有行业,但它能激发更多人的创作力。他表示,“Sora只是小试牛刀,它展现的不仅仅是一个视频制作的能力,而是大模型对真实世界有了理解和模拟之后,会带来新的成果和突破。”
他解释说,“机器能生产一个好视频,但视频的主题、脚本和分镜头策划、台词的配合,都需要人的创意至少需要人给提示词。”他强调,科技竞争最终比拼的是人才密度和深厚积累。
而对于Sora当前存在的弱点,OpenAI也明确指出,它可能难以准确模拟复杂场景的物理原理,并且可能无法理解因果关系。该模型还可能混淆提示的空间细节,例如混淆左右,并且可能难以精确描述随着时间推移发生的事件,如遵循特定的相机轨迹。而这些缺陷可能导致Sora生成一些不合逻辑的东西,比如一个人在跑步机上跑错方向,以不自然的方式改变主题,甚至出现凭空消失的现象。
滥用仍是最大的担忧
随着名人、政客等人物的深度造假视频在网上变得越来越普遍,相应的伦理和安全问题也让人心惊,尤其是在总统选举年和紧张的政治局势背景下。
Gartner分析师Arun Chandrasekaran表示,“鉴于这项技术确实非常新,他们必须对其进行充分控制,以防止其被滥用和误用,甚至客户在没有认识到这项新兴技术所有局限性的情况下使用它。”他补充道,OpenAI为该模型设置的防护措施以及确定谁可以获得访问权限至关重要。
牛津互联网学院客座政策研究员Mutale Nkonde也表示,任何人都可以轻松地将文本转换为视频这一想法令人兴奋。但同时,她也担心这些工具可能会植入社会偏见和仇恨内容,对人们生活造成影响等。
普林斯顿大学计算机科学教授Arvind Narayanan对此也有担忧,认为Sora这类技术可能会导致“深度伪造”视频,让人们难以识别。虽然AI制作的视频仍会有一些不一致的地方,但普通人可能不会注意到这些细节。“迟早,我们需要适应现实主义不再是真实性的标志这一事实。”
针对业界的担忧,与此同时,监管机构也在加强管理。美国联邦贸易委员会(FTC)2月15日提出了禁止使用AI工具冒充个人的规则。FTC表示,它正在提议修改一项已经禁止冒充企业或政府机构的规则,将保护范围扩大到所有个人。







 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


